Because beginners do not need to understand what the heck is going on under the hood of JS. Just: watch, mimic, code and repeat until we get familiar with them. After all, JS handles everything for us.
1) JavaScript vs Browser
Pic 1: JavaScript in browser
Before we move ahead, we need to have a look at these terms:
Runtime: execution time. It is totally different with compile time. For example browser, NodeJS.
JavaScript: is an interpreted and single-thread programming language. But the JS runtime is definitely not.
Browser: provides Web APIs (AJAX, DOM, Timeout), queue (callback queue, promise queue), and event loop.
Pic 2: JavaScript in browser 2
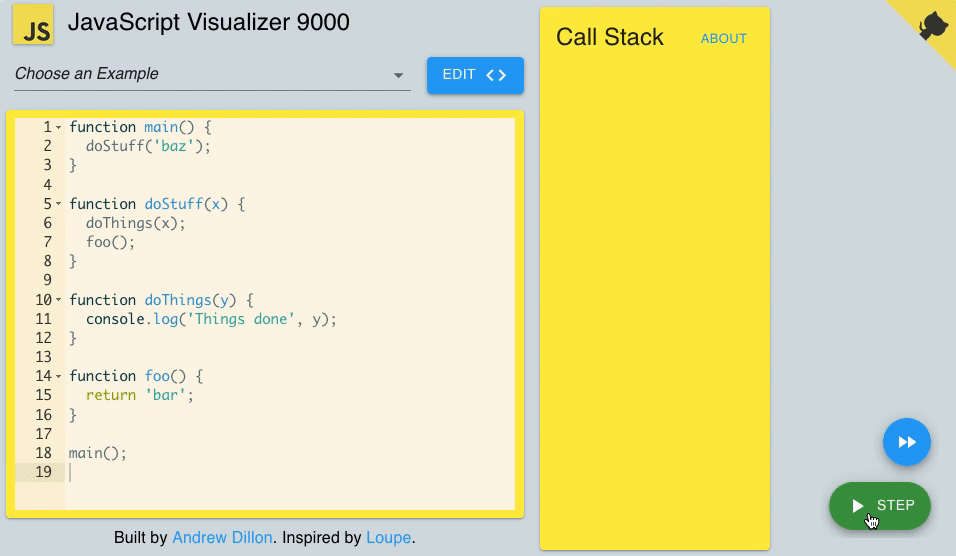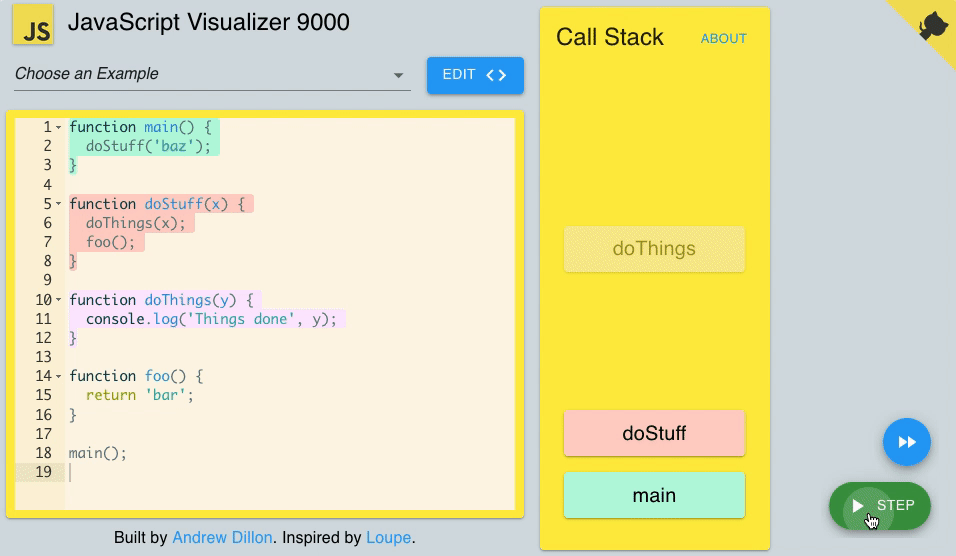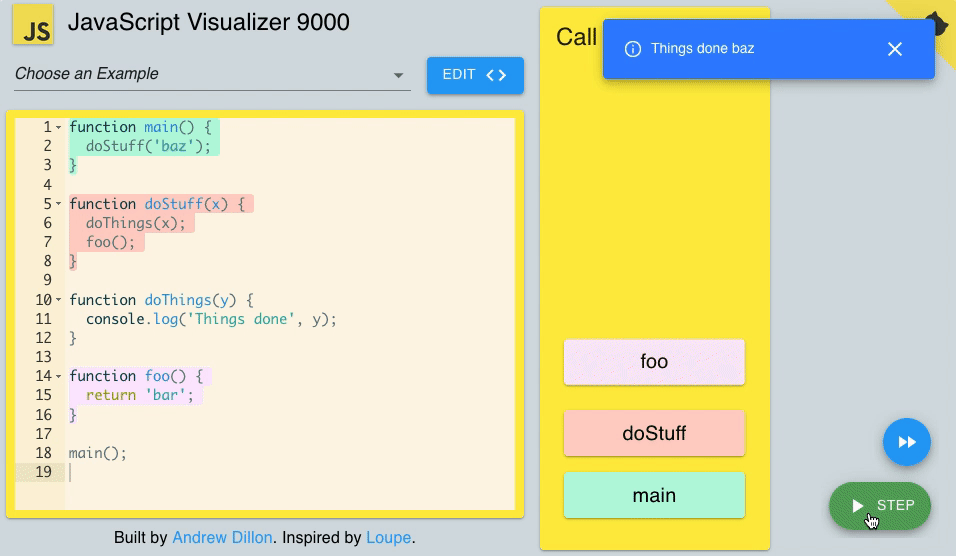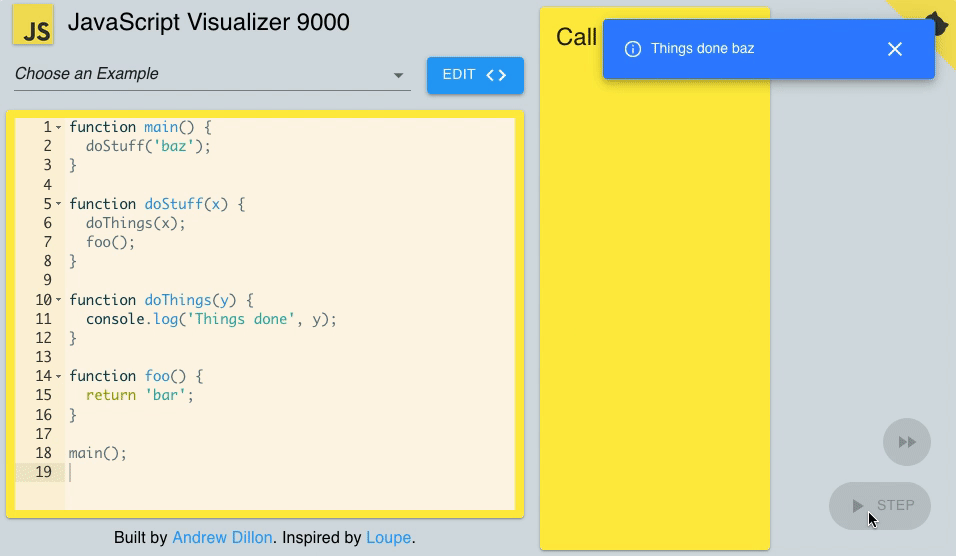
2) Call stack
As I mentioned above, JavaScript is a single-thread programming language. It means JS can do one single thing at a time. Why??? Because it has only one call stack.
Call stack is a mechanism that helps the JS interpreter to keep track of functions that a script calls and follows the FILO (First In, Last Out) principle.
Every time a script or a function calls a function, it is added to the top of the call stack.
Moreover, when a function exits, the interpreter removes it from the call stack.
The error above is a typical error that developers usually summon :). Because the browser limits the maximum size of call stack (about 10-50k calls) to prevent our code from freezing.
3) Heap
Heap (dynamic allocation) is a place where objects are stored. Basically, it doesn’t affect the call stack and event loop.
4) Web APIs
JS can do only one single task at a time. That’s why Webapp will be impractical, and Browser provided us with Web APIs (AJAX, DOM, Timeout) which are written in “lower-level language” (C), so we can call Web APIs in our JS code. The execution is handled by itself and won’t block the call stack.
For example we are now able to do tasks concurrently outside of the JS interpreter.
5) Callback queue
We do know that we are going to get a response after calling the Web APIs, so how can we handle the result of that in our JS code?
Pic 4: Callback queue
That’s where the callback comes into play. Through them, Web APIs allow developers to run code after API calls has finished.
Callback waits until the call stack is empty and it will be added after the last task has finished in the call stack.
Basically, callback is naturally not the asynchronous function. And the “parent function”, which takes a callback as an argument, is called Higher Order Function (HoF). And the callback queue follows the FIFO (First in, First Out) principle.
6) Event loop
The Event Loop is responsible for taking the first call from the callback queue and adds to the call stack. It is blocked when the call stack is currently executing and won’t add any calls until the call stack is empty again.
Important: not to block the call stack by running intensive task. Because it gonna freeze our website for a while until that tasks have finished.
7) Job (promise) queue and Asynchronous code
On the other hand, callbacks caused a critical problem in our codebase as well as the DX (developer experience): Callback Hell or The Pyramid of Doom.
Pic 5: Callback Hell
That’s the reason why Promise was born to save the developers’ life. The Promise has the “chain” property that let us write the better codebase.
Pic 6: Promise
Does it look better right? No matter how many functions you need to run continuously, they are still written in a straightforward way, from the first to the last one. Moreover, in the underhood of the JS system, the Promise Queue has priority over the callback queue. It means that if the call stack is empty, a promise and a callback are waiting; the event loop always adds the promise first and then the callback.
8) Conclusion
Through this article, I hope you guys understand how the ground of JS works, and we can avoid getting in trouble with typical errors such as call stack size exceeding or freezing websites.



{kind=link}



